I have 1,113 bookmarks saved on X since January 2025. Last week I sat down and tried to count how many of them I had ever opened a second time. The honest answer was almost none.
That bothered me more than it should have. I save things on X all day. I mostly use X to stay tuned and to learn about technology and topics I’m interested in. So whenever I see a sharp thread, a research paper or a tool someone shipped over the weekend I always save it to check it out later.
But every time I tap the bookmark icon, a small part of my brain checks a box: handled, I have that now. And then I never see it again.
Saving something is not the same as knowing it. A bookmark folder is not a library. It is a graveyard with good intentions, and if you use X seriously, you almost certainly have one too.
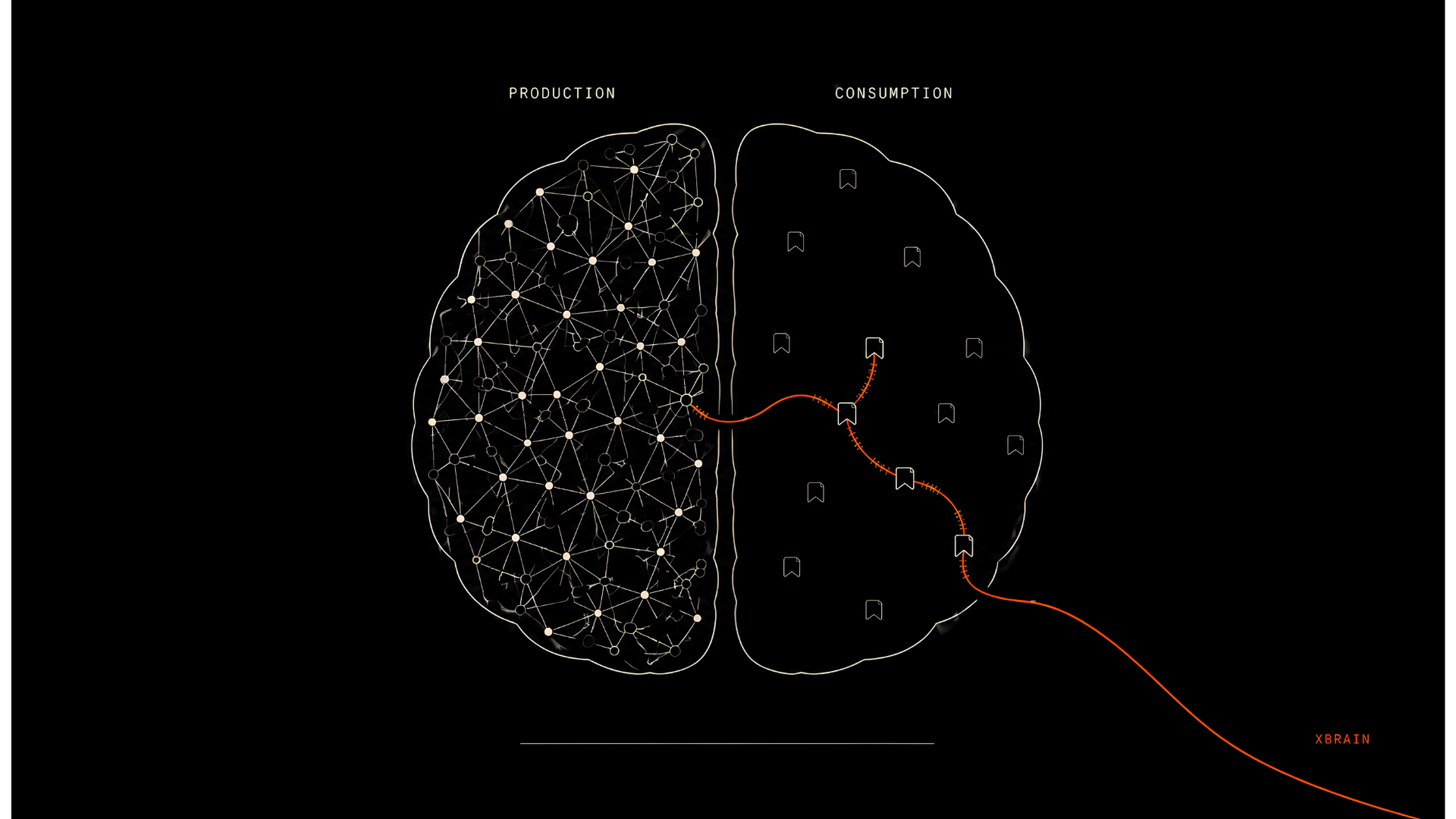
A second brain with a hole in it
I have kept a second brain since late 2025. A large Obsidian vault, the place where I actually think: project notes, decisions, drafts, an almost daily journal. The more I work, the bigger and more useful it gets. My AI agents read from it. It is, honestly, the most valuable thing I own as a knowledge worker today. Its value compounds over time, specially when combined with a troop of agents that process its information and bring them to me whenever I need it.
But it has a hole in it, and the hole is the exact shape of everything I consume.
A personal knowledge base captures your production. It captures nothing of your consumption: the articles you read, the threads you save, the posts you write on a platform that is not your vault. And consumption is knowledge too. At least to me.
Those 1,113 bookmarks were not noise. They were sixteen months of me deciding, link by link, that something was worth keeping. That is a strong signal about what I care about and how my thinking moves, and I was throwing it on a pile and walking away.
So my second brain remembered everything I said and forgot everything I heard. It was half a brain.
So I built XBrain
I did not want a better bookmark manager. I wanted the consumption side of my brain to live in the same place as the production side. In Obsidian, in the same graph, linkable to every note I already had.
So I built that. It is a tool called XBrain, and it pulls my bookmarks and my own posts out of X and turns them into a wiki inside my vault.
Why I could not just use the API
The obvious way to get your data out of X is the official API. That door is closed. The free tier is essentially write-only, and the endpoint that returns your own bookmarks sits behind a paid plan at around 200 dollars a month. I was not going to pay a subscription to read links I had saved myself.
So XBrain does not touch the API. It opens X the way I do, in a real browser with my own logged-in session, and it reads the same data the X web app reads. The web app talks to X’s own internal endpoints; XBrain listens to that conversation and keeps a copy. No API key, no paid plan, no scraping of rendered pages.
One important note before continuing. XBrain reads X through endpoints X never published for this. I run it on my own account, with my own data, slowly, for myself. Treat it the way you would treat any tool that automates your own browser, and not as anything more.
How XBrain works
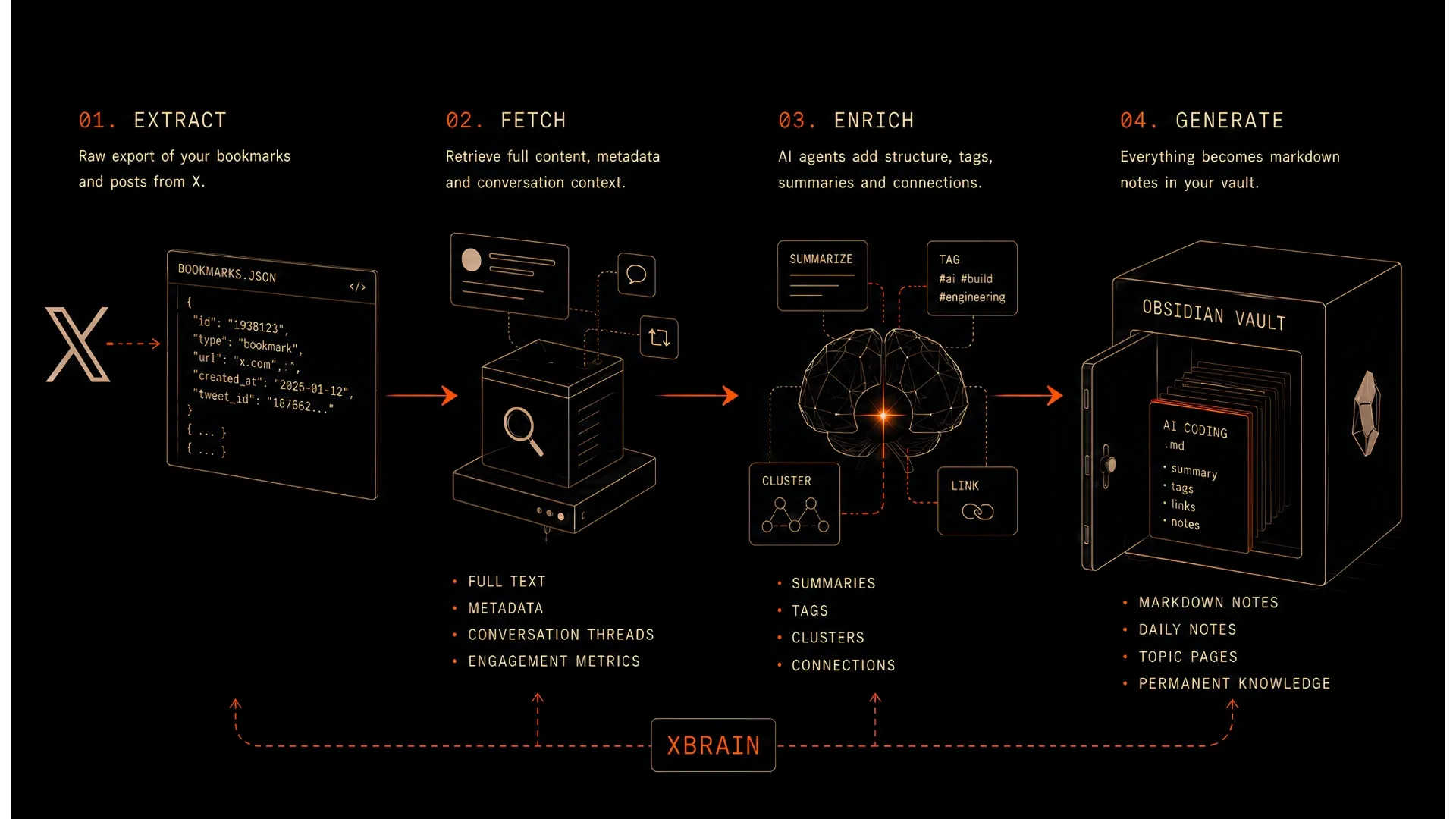
I built XBrain as a small pipeline. Each stage does one job and hands its result to the next. Extract pulls the data out of X. Fetch downloads the full text of every article I had linked to, so a saved link becomes a saved article. Enrich processes it. Generate writes the result into the vault.
Getting the data out cleanly took more care than I expected. X does not want a script reading its internal endpoints, so XBrain does not behave like a script. It scrolls slowly, at human speed, with random pauses, and it never asks for more than a person browsing would. It also anchors to the names of X’s internal operations rather than their identifiers, because X rotates those identifiers constantly and anything that depends on them breaks within weeks. Slow and boring, on purpose.
The decision that holds the whole thing together is underneath all of that. The source of truth is a single structured file, plain and boring JSON. In other words, the Obsidian wiki is not the database. It is a rendering of the database. This layer separation allows, for instance, that when I want to change how a note looks, I do not go back and scrape X again. I regenerate from the JSON directly. The expensive step, getting the data, happens once. The cheap step, shaping it into something readable, can happen a hundred times. Separate the data you cannot easily recreate from the views you can. That is an old lesson, and it is the difference between a tool you keep and a tool you rebuild.
From a backup to a brain
As I said, XBrain runs in two phases.
The first phase is pure extraction. In my last extraction it went through 1,870 items from the last sixteen months: 1,113 bookmarks and 757 of my own posts. For every item that pointed somewhere, it pulled down the full article behind the link. 137 articles, captured whole, instead of 137 URLs that would quietly rot.
So at the end of phase one I had a clean, complete copy of everything I had saved and said on X. Useful, but still a pile. A tidy pile is still a pile.
The second phase is where it becomes a brain. A set of AI agents read all the extracted items worth keeping, one at a time. In my case, 1024 entries. Each item gets a short summary and is tagged against a fixed set of topics. The fixed set matters: let a model invent its own categories and you get four hundred of them, each with three notes. A small, closed vocabulary is what makes the topics usable. The output was not 1,024 loose notes. It was 1,024 notes that know what they are about and how they connect.
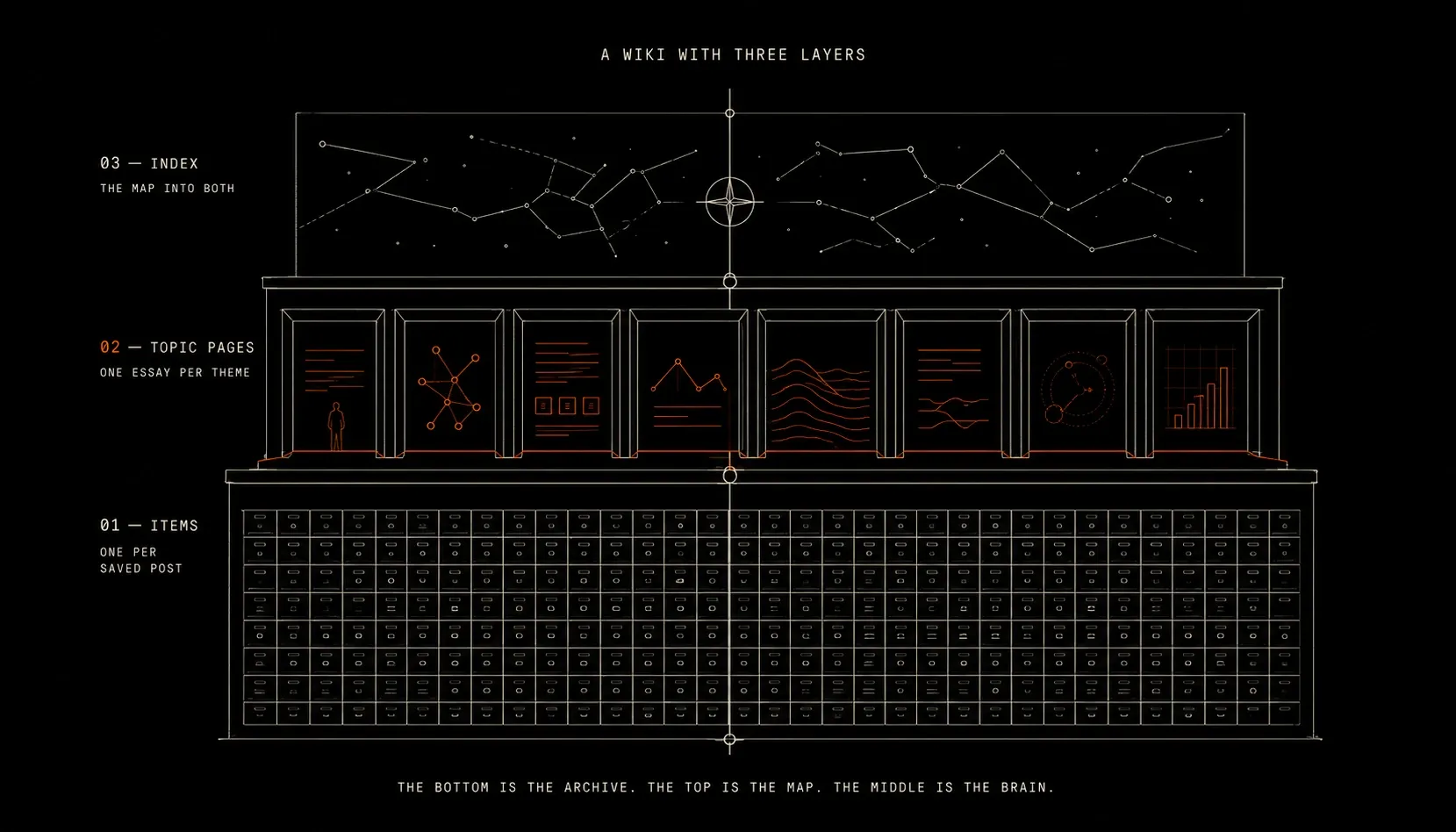
The topic pages
The result is a wiki in my vault with three layers. The bottom layer is the items: one note per saved thing, with the original text, the link, the full article and its tags. The top layer is an index, the map into all of it. The middle layer is the one I did not see coming how useful would it become.
The middle layer is 30 topic pages, one per theme. And a topic page is not a list of links. It is an essay.
XBrain took my 231 posts and bookmarks about AI coding, read every one of them, and wrote a single synthesis: where my thinking started, how it moved, and what I kept circling back to. It traces my own arc across sixteen months, from Cursor and “vibe coding” at the start of 2025, through the week Claude Code arrived that July, to spending my days orchestrating teams of agents. It even handed me back the line I had been circling for a year without admitting it was my thesis: code is not the input anymore, specs are. Every claim in that essay links straight back to the post that supports it.
I read it and felt slightly strange. It was the most honest account of how my thinking changed last year, and I never sat down to write it. I had written it already, 231 times, in fragments, without noticing. XBrain just collected the fragments and held them up in front of me.
You can do this too
None of this is specific to me. If you use X as a feed of things worth keeping, you already have the raw material. It is sitting in your bookmarks right now, doing nothing.
The recipe is not complicated. Get your data out onto your own machine, without paying a toll for it. Keep the real source in a structured, boring format you can regenerate from. Then let a model do the one thing it is genuinely good at here, which is reading a large pile of text and telling you what is inside it. The destination does not have to be Obsidian. It has to be wherever you already think.
Closing
For sixteen months my consumption and my production lived in two separate worlds. What I read was trapped inside X. What I wrote was in my vault. XBrain put them in the same graph, and the moment it did, my notes and my bookmarks started linking to each other. That is the whole point. A second brain that only remembers what you produced is half a brain. Joined back to what you consumed, it is finally the thing it was always supposed to be.
XBrain feeds my classes at IE now, and it keeps me honest about how my own thinking actually moves. The next step is making it keep itself up to date without me touching it.
I am open-sourcing XBrain. If you have a bookmark graveyard of your own, I want you to be able to point a tool at it and get a brain back, so the code is public: github.com/VGonPa/xbrain. And if you build something with it, or it breaks in your hands, I would like to hear about it. You can reach me through my email page.