
In June 2025, Google made Gemini 2.5 Pro generally available. We spent that week at FITIZENS watching its video demos, and one question would not go away: could a model watch an athlete train and judge how well they moved? I am not talking about counting reps, but judging form. That is, could it tell a clean pull-up from a sloppy one, or a safe squat from a dangerous one?
That question became the FITIZENS Video Coach. We started testing within days, from the end of June into mid-July.
It was thrilling, and it was unusable.
We tried it with clean videos of athletes doing squats, snatches, and other olympic lifts. The feedback came back sharp and genuinely useful. But it was not consistent. The model would quietly change its mind about what mattered. Feed it the exact same video several times in a row and it would still come back with a different answer each time, coaching depth on one run and waving it through on the next. Show it two different athletes and it would judge each against criteria it seemed to invent for that one clip. Each piece of feedback was good on its own. It just was not the same kind of good twice.
A demo tolerates that. You keep the clip that worked and you show that one. You can even produce good videos for X or Youtube if you want virality. But a product that a paying athlete trusts with their training does not get to choose its clips. Every athlete, every exercise, every rep has to be judged by the same standard, or the product is quietly lying to them.
Closing that gap took us a few months of work. Part of it was the model and its tooling: the kind of step-by-step reasoning we needed to judge a movement was not dependable enough yet in mid-2025. The larger part, the part we could actually control, was less glamorous. It was guardrails.
This post is about what guardrails are, the two kinds that matter, and why each one matters, told through a system, FITIZENS Video Coach, that did not work until it had them.
One honest caveat first. Guardrails are not the whole story: a capable model, a sound workflow, and real evaluation all matter too. But guardrails are the piece most teams skip, and the piece with the highest payback for the hours you put in.
Why this happens to everyone
The inconsistency was not a bug. It was the technology doing exactly what it does.
A large language model does not compute an answer. It generates one, token by token, by sampling from a probability distribution. Run the same input through it twice and you can get two different outputs. Turning the temperature down to zero narrows that variation, but it does not close it: the same model, running on shared and batched infrastructure, still drifts from one run to the next. Variation is not a defect of an LLM. It is what an LLM is.
For a chat assistant, that variation is a feature. Nobody wants the same brainstorm twice. For a product, it is a structural problem, because a product makes a promise. Our promise was that an athlete’s squat would be judged by the same standard as every other squat, theirs and everyone else’s. A model that judges each clip a little differently cannot keep that promise, no matter how good any single judgment looks.
And you cannot fix this by writing a better prompt. Believe me, we tried. The prompt does not change what the model is. You can ask it, very nicely and in great detail, to apply consistent criteria, and most of the time it will, and “most of the time” is exactly the problem.
This is where guardrails come in, and where most explanations of them go slightly wrong.
A guardrail does not make the model deterministic. The model stays stochastic. What a guardrail does is make the system around the model observable, bounded, and, above all, verifiable: it checks every result against something explicit, and it rejects, retries, or corrects whatever does not pass.
Think of a workshop with a machine that is brilliant but slightly inconsistent. Most of the parts it stamps out are perfect. Some come out a fraction of a millimetre off. You do not fix that by asking the machine to concentrate harder. You put an inspection gate at the end of the line: every part gets measured, and only the ones inside tolerance go in the box. The machine stays inconsistent. The line still ships only good parts.
A guardrail is that inspection gate. The model is the machine. “Inside tolerance” is the contract you decided on in advance. The output you ship is never the model’s raw output. It is the model’s output that passed the gate.
That is the whole game. Everything else here is detail.
What a guardrail actually is
Search for a definition of “guardrails” and you find a dozen. Most agree on a narrow one. The toolkits people reach for, NVIDIA’s NeMo Guardrails, the Guardrails AI library, the OpenAI Agents SDK, all describe roughly the same thing:
A guardrail is a control that constrains what goes into or comes out of a model, checking it against a policy, and it sits around the model rather than inside it.
That definition is correct. I also think it is incomplete.
It is shaped by where guardrails get sold, which is safety and compliance: block toxic content, redact personal data, stop jailbreaks, etc. All real, all necessary. But that framing makes a guardrail sound like a bouncer, something that stands at the door and turns away the bad stuff. Once you are building a real agentic system, that picture leaves out the most useful part.
Here is the definition I would argue for:
A guardrail is a control that forces the input or output of an agent to satisfy an explicit, machine-checkable contract. It blocks what breaks the contract, and, just as importantly, it tells you exactly what broke and where.
Blocking the bad output is the obvious half. The other half is what makes guardrails worth the trouble. A guardrail turns a fuzzy question, “is this output any good?”, into a definite one, “does it satisfy the contract, yes or no?”. A fuzzy question cannot be automated. A definite one can.
Think of it as a code linter for your agent. A linter does not just refuse to compile bad code. It points at line 42 and tells you the variable is never used. A guardrail that only says “rejected” is half a guardrail. A guardrail that says “the depth score for squat-exercise is missing from repetition three” is one you can act on, and, more importantly, one another agent can act on: you hand that exact failure back, and have it fixed. A good guardrail does not just stop the error. It locates it, names it, and makes it fixable.
That is why a guardrailed system becomes verifiable, repeatable, and debuggable, and a stochastic system that is verifiable and repeatable is one you can actually put in production.
There is one more thing the bouncer framing misses. In an agent with more than one step, the output of step one is the input of step two. If you cannot check that output, you are building step two on a foundation you never inspected. A guardrail is the checkpoint between the steps: each step hands its work to the next only once that work has passed. It is not only a filter at the edge of the system. It is what makes a multi-step agent trustworthy from the inside.
I am not going to tell you the narrow definition is wrong. It is the industry consensus and it is useful. But if you are building agents, and not only moderating them, the wider one is the definition that will serve you.
If you have never built an agent before, this may seem abstract to you, but it is only until you see them in action. So here are a few guardrail examples from real systems:
- A sentence in the system prompt telling the model never to give medical advice.
- A rule that the model must answer as a structured object with a numeric
scorefield, or the answer is thrown away. - A check, in code, that a support agent’s drafted refund above fifty euros is held for a human.
- A script that blocks a coding agent’s pull request if test coverage dropped.
Look closely and those four split into two very different kinds. That split is the most important thing to understand about guardrails, so it gets its own section.
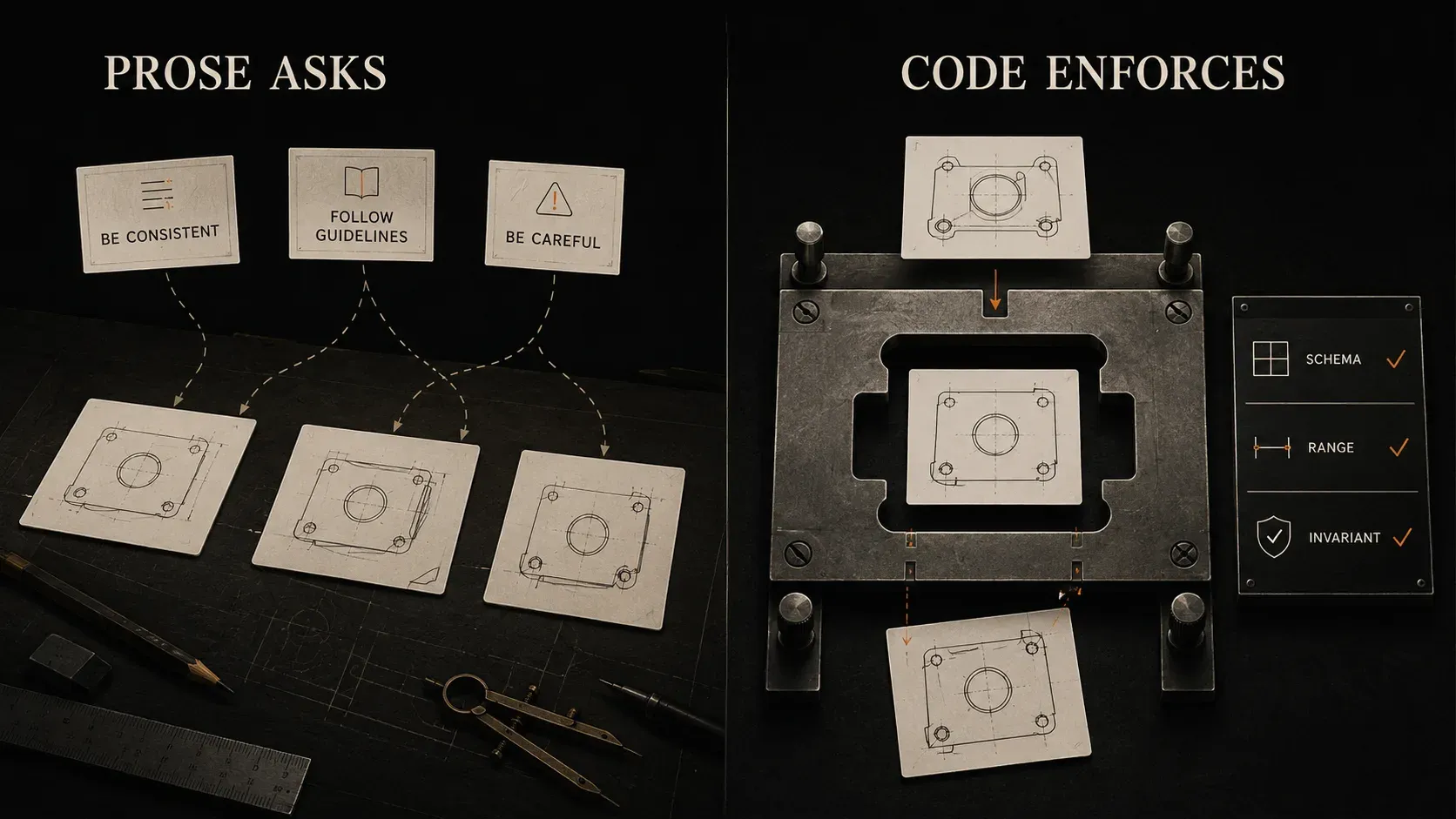
Two layers: prose and code
The two kinds of guardrail are written in completely different places, and confusing them is the most expensive mistake in this area.
The first kind is written in prose. It is an instruction in the system prompt. The FITIZENS Video Coach prompt is full of them, and they are some of my favourites. One tells the model that if two repetitions in a row come back with word-for-word identical descriptions, it is not watching the video any more, it is generating from memory, and it should stop and look again. Another reminds it that a person cannot teleport, so a body position has to change gradually from one frame to the next.
Those are guardrails. They are cheap to write, they cost almost nothing to run, and they genuinely help. But they have a property you cannot design away: they are requests. A model follows a prompt instruction because that instruction makes the right answer more probable, not because anything forces it to. On a good run it follows all of them. Across ten thousand runs, “usually” is not a number you can build a product on.
The second kind is written in code. It runs outside the model, after the model has answered, and it does not negotiate. Some examples:
- A schema the response has to match, checked by a parser. Wrong shape, rejected.
- A range check: a score outside 0 to 100 is rejected.
- An invariant: a total has to equal the sum of its parts.
- An allowlist: the agent may call these three tools and no others.
- A quality gate: for instance, I run scripts on every pull request my coding agents open. They measure cyclomatic complexity, test coverage, security warnings, dead code, etc. If the numbers move the wrong way, the pull request does not merge. Those scripts are guardrails too, around a different kind of agent.
If the output fails one of these, it fails. The model does not get a vote. That is the whole difference: a prose guardrail asks, a code guardrail enforces.
The industry has converged hard on this. OWASP’s 2025 guidance on prompt injection is blunt: put your guardrails outside the model, treat the model as an untrusted user, and validate its output with an external mechanism instead of trusting instructions in the prompt.
But the lesson is not “prose bad, code good.” You want both, because they do different jobs. The prose guardrail lowers the chance the failure happens at all. The code guardrail makes sure that if it happens anyway, it never reaches the user. Anthropic calls this chaining safeguards: a cheap soft layer first, a hard expensive layer behind it. The soft layer is your prevention. The hard layer is your guarantee.
The types of code guardrail
Within that code layer there are a handful of distinct guardrails. The useful way to learn them is not as a taxonomy to memorise, but as answers to specific failures. These earned their place in our system, and you will recognise them in most others.
Input validation: check what the agent is about to receive, before it runs. Is the uploaded file actually a video, in a format we support, under the size limit? Is the user’s message a reasonable length, or is it fifty thousand tokens of pasted noise? This is the cheapest guardrail, and it catches the failures that were never the model’s fault. A surprising share of “the agent is broken” is really “the agent was handed garbage.”
Structured output: force the answer into a shape, not prose. Instead of letting the model reply in free text, you require a structured object that matches a schema: a score that is a number, a level that is one of a fixed set, a feedback field that is present and non-empty, etc. This is the foundation the other guardrails stand on, because you cannot run an automated check on a paragraph, but you can run one on a typed object. When the schema is enforced by the model’s API through constrained decoding, it becomes the one genuinely deterministic guardrail in the stack: the model is mechanically unable to produce output that breaks the shape. OpenAI’s structured outputs is built on exactly that. But one honest caveat: a schema guarantees shape, not truth. A response can match the schema perfectly and still be wrong. Structured output is necessary. It is not sufficient.
Invariant checks: the content has to obey the rules of your domain. The schema says the shape is right; an invariant says the values make sense. A score has to fall inside the set of quality levels you defined, so the model cannot quietly invent a new one. A workout’s total time has to equal the sum of its intervals. And the invariant that mattered most for us: the right criteria depend on the exercise. Judging a pull-up is not judging a squat, and it is not judging a snatch. Each movement is good or bad for different reasons, and a single generic schema cannot hold that. The guardrails have to be as specific as the domain, or they are not guardrails, they are decoration.
Cross-verification: a second pass checks the first. A separate step, often a separate agent, re-reads the output and checks it against the standard. This is how you catch the failures that look perfectly reasonable on their own and are only wrong in context, which is exactly the failure the Video Coach had: each judgment looked fine, the set of them was inconsistent. This is the most powerful quality guardrail there is, and it is large enough to deserve its own post, so I will come back to it later in this series.
Tool and budget limits: cap what the agent can do and spend. Which tools it may call, how many steps it may take, how many times it may retry, how much it may spend before something stops it. For an agent with real autonomy these are essential. For a fixed workflow like ours they mattered less, so I name them and move on.
How we did it at FITIZENS
Concretely, then. Here is how those layers fit together in one real system.
The backbone is a set of schemas, more than fifty of them, one per kind of output an agent in the system produces. Each schema is a contract: this is the shape, these fields are required, this number lives in this range, this value is one of these options, and so on. The schema is the same whether the agent is judging a squat or a snatch, so the structure of an answer never depends on the exercise or the day.
On top of that we run both layers. The prompt carries the prose guardrails, the ones about not generating from memory and not letting a body teleport. The code carries the hard ones: the schema validation, the range and invariant checks. And then a separate step cross-checks the result, because the failure we cared about, inconsistent standards across reps, is invisible to any single check and only shows up when you compare.
Here is the example that makes it concrete. Every piece of feedback the Video Coach gives, for every rep, has the same structure. The model is free, genuinely free, to phrase the coaching, to notice what is interesting about this particular rep, to be useful. But the guardrails make sure that freedom happens inside a fixed frame: the feedback always fills certain fields, never strays into certain territory, and only proposes improvements within a sane range. Freedom inside a structure. That phrase is most of what we learned in a year.
This is also where guardrails and rubrics meet, and it is worth being precise, because the terms are easy to mix. A rubric is the set of criteria: what counts as a good pull-up. A guardrail is the enforcement: what makes the model actually fill that rubric in, every time, completely. We expressed our rubrics as structured output, so the rubric became a schema and the schema became the guardrail. The rubric is the standard; the guardrail is what holds the model to it. Rubrics deserve their own post, and they will get one in this series.
None of this makes the agent perfect. Guardrails do not remove failure. They bound it, and they make it visible. That is a smaller promise than “reliable AI,” and a much more honest one.
Anti-patterns
A few mistakes that are common enough to name.
“The model is good enough now, it does not need validation.” It is stochastic. It will produce the bad output eventually, and at production volume eventually means this week.
Treating the system prompt as a guardrail. A prompt instruction is a suggestion the model usually takes. Usually is not a guarantee, and a guardrail is supposed to be a guarantee.
Schemas so loose they validate anything. A schema that accepts any object enforces nothing. If it never rejects, it is documentation, not a guardrail.
Guardrails in production but not in development. Then dev and prod diverge silently, and you discover the gap from your users.
Not logging when a guardrail fires. Every firing is a labelled example of a failure mode. Throwing that away is throwing away your best source of improvement.
Confusing shape with truth. Schema-valid is not the same as correct. The schema is the floor, not the ceiling.
How to start
If you take one practical thing from this, take this: add guardrails from the first iteration, not the first incident. Early, a guardrail is scaffolding. Added late, after the architecture has hardened around its absence, it is debt. The payback on doing it early is large enough that it is close to free.
A few more, some from our own scars and some that are simply the industry consensus now:
- Expect them to change. Guardrails are not write-once. They iterate as the agent iterates. When the agent’s scope grows, the guardrails have to grow with it, or they drift into being too loose to catch anything or too strict to let valid output through.
- Adopt them in order. Start with the output schema, because it is the foundation. Then invariants. Then safety and refusal logic. Each layer is easier to build once the one under it exists.
- Layer them. No single guardrail is complete. Prose plus code plus cross-verification. Defense in depth is the consensus for a reason.
- Treat the model as an untrusted user. Validate at the boundary. Do not assume good faith from the output just because the model is usually well behaved.
- For agents, check the trajectory, not just the final answer. An input that looks clean at step one can trigger a bad tool call at step three.
- Instrument every firing. A guardrail you cannot see fire is a guardrail you cannot improve.
Closing
Guardrails are not the exciting part of an agent. Nobody demos their schema validation. But they are the inspection gate that lets the exciting part reach a real user: every athlete, every exercise, every rep, and not just the clip that happened to work.
They are also only one pillar. A capable model, a sound workflow, honest evaluation: a real agent needs all of them. And the most powerful guardrail of all is not a schema. It is a full system that judges the quality of the output against a standard, and that is the next post in this series.
We spent the back half of 2025 learning this the slow way, mostly by shipping things that were not ready and watching them wobble. If you are building agents, and any of this sounds familiar, or wrong, I would like to hear about it. Email me.